To unlock the value of data in an enterprise it is critical to establish an efficient data engineering process which can process data residing in varied forms and structures. With various open-source alternatives, cloud-native services, and cloud-agnostic products, there is a plethora of data engineering design patterns that can be architected.
Electronic Health Records (EHR) is a combination of structured and unstructured data with strict data privacy regulations. Establishing a well-designed data engineering process is essential for seamlessly onboarding new EHR datasets. Leveraging a tech stack featuring AWS Glue Crawler and Catalog, alongside Athena, offers an excellent solution for efficiently scanning and onboarding EHR datasets.
For our large global consulting client, the processing of EHR data is designed using AWS services such as EventBridge, SQS, Lambda, Glue, Athena, and dbt. dbt is a popular choice among SQL enthusiasts, simplified the task of data transformation by establishing a common framework that we leveraged across the data engineering team. dbt is integrated with Glue Catalog for the metadata, and it pushed down all the calculations at the Athena level, making the entire transformation process faster and easier to maintain.
Following diagram depicts how the AWS services interacted across Ingestion, Cataloging and Transformation.
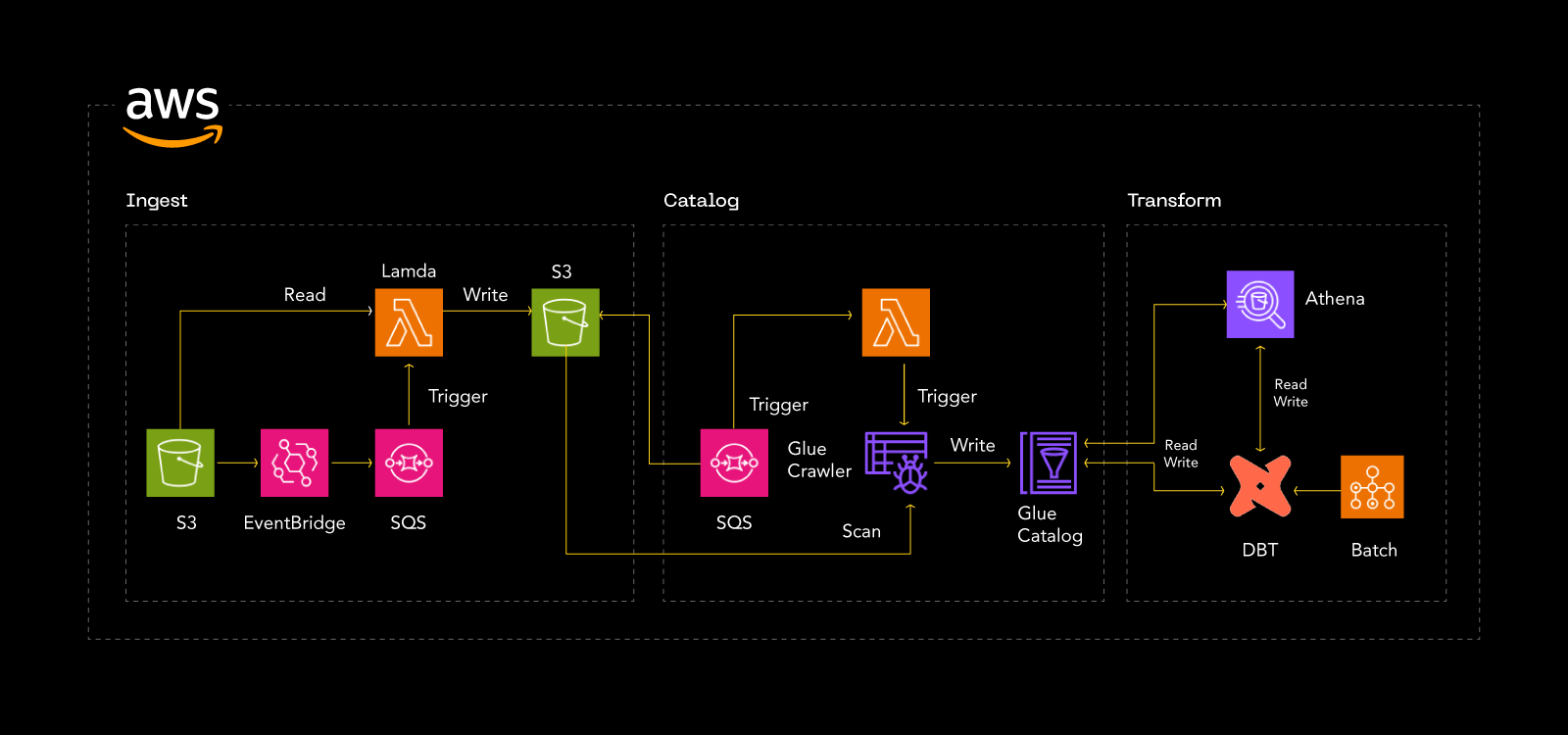
Ingest
The files came through two modes, one by uploading the files through a web application and the other through an automated file transfer. All files reach a specific S3 bucket. Some of the validation rules implemented include.
- Right delimiter is present or not
- Number of columns in the file
- Missing values for specific fields
- Duplicate rows
- Incorrect data format
Utilizing AWS services for automating data ingestion involves the following steps:
- When a file is uploaded to an S3 Landing Bucket, it triggers an event notification.
- The notification is directed to an SQS queue
Upon receiving the event notification, a Lambda function is invoked to copy the data
Catalog
Glue Crawlers automatically scan and infer the schema of data sources and create metadata tables in the AWS Glue Data Catalog, which is used by dbt for data transformation and loading. Crawlers can be configured to run on a schedule, on-demand, or in response to an event.
In EHR data processing crawlers are configured as event based, when an event occurs in associated SQS queue, crawlers will crawl the prefixes (collected from the event) not every folder in S3 bucket.
Crawler Trigger lambda function performs the following operations:
- Reads the event messages in SQS Queue and get the prefixes.
- Executes the crawler, updating the data catalog with the newly ingested file’s metadata
Transform
Transform Segment is a collection of AWS Batch resources that enable developers to run batch compute workloads on AWS Cloud. This runs batch computing workloads on AWS cloud & provisions compute services and optimizes workload distribution based on quantity and scale of the workload.
In AWS Batch,
- Job definition is a template that specifies the configuration of a job. The job definition includes information such as the ECR image URI, number of vCPUs, memory, etc.
- Job is the instance of a job definition, and it is submitted to a job queue
- Job queue is a queue where the job resides until it is scheduled to run.
- Compute environment is a set of managed or unmanaged compute resources that are used to run jobs.
In EHR data processing the compute segment is delivered by dbt. dbt configs and files are maintained in a separate repository. The namespace of model configurations is set to a specific name and the model directory structures are configured under that namespace. Each of the directory names indicates a stage of the platform and the various data models (.sql files) pertaining to that stage. Key config files include
target.yml : Set of profiles are present in the file, where each of them consists of targets (Types of databases to connect), credentials to connect to that database.
project.yml: This is the main configuration file of the project which is what dbt uses to determine the project directory structure, what each of the directories means, and how to operate on project. It is the starting point of the project and runtime execution.
The batch executes the dbt commands and creates the tables/models in the mentioned target like Glue catalog, Athena. Subsequently, Users utilize AWS Athena to query and analyze the cataloged data effortlessly.
Ascendion AVA Data Onboard Express (DeX) enables rapid onboarding of data into data lake leveraging metadata-driven ingestion, Gen AI-assisted data validation and configurable orchestration delivering higher productivity and reduced TCO.
Ascendion AVA DeX brings together the best of various Data Engineering design patterns by leveraging a combination of open-source and cloud-native services. Key benefits delivered by Ascendion AXA DeX includes.
- Achieve up to 60% reduction in data onboarding time and effort through automated Data ingestion
- Utilize Metadata-Driven Reusable Assets to expedite Enterprise-wide adoption
- Deploy standardized artifacts for simplified maintenance
- Gain instant access to data with an Event-Driven Architecture
- Facilitate data analysis with streamlined Data Cataloging




